Thoughts on ProgramBench Part 1
Meta (in conjunction w/ Stanford + Harvard) released a paper last week called ProgramBench detailing the state of language models for writing code repos. It consists of the paper, the github to run the eval, and the huggingface link to download the test blobs.
They defined the task by scraping 200 github repos based off some heuristics, generate tests using a synthetic pipeline, then feed the golden compiled program and the repo’s documentation to mini-swe-agent and have it generate the repo + a build script. The build script + code is then ran against the synthetic TB.
Notably, they found that no runs resulted in a 100% TB pass although a couple runs came close. I had some thoughts on how this experiment was carried out and wanted to dive into them in this post.
A full recreation of the repo w/ the necessary modifications to run my experiments can be found at my fork. I’ve added support to make single runs w/ Openrouter as a provider.
- main repo is eval only, I’ve added the steps + extra code to pull the TBs + run the task
Fast run through of paper
Following images are from the paper.
Tasks were created by scraping Github w/ some heuristics to create testbenches. TBs were made in Python using mini-swe-agent w/ Sonnet 4.5 (interesting choice given they had access to better models).
The hand icon is mini-swe-agent’s logo and refers to an agentic step. mini-swe-agent is a lightweight single agent pipeline/flow, comparative to claude-agent-sdk.
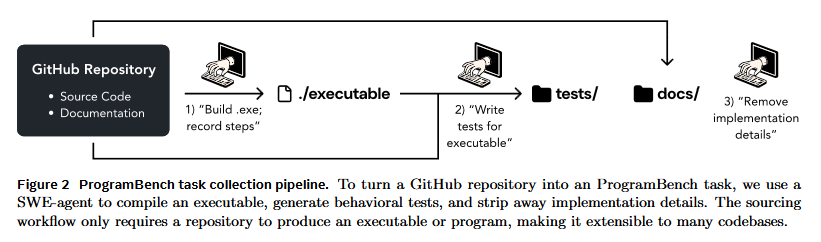
The authors have provided docker images per task, and run the agent in there w/ network access disabled along w/ some additional checks to prevent cheating.
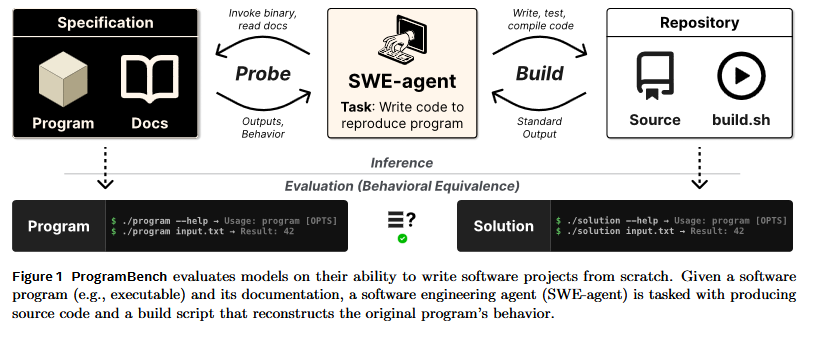
Thoughts on Methodology
None of these ideas were created by AI, they occured to me as I read the paper.
1 - task formulation
The goal of the paper is “to measure the ability of software engineering agents to develop software holisitically”. Having the golden executable when creating software seems like a bit of a stretch.
I see the reasoning for it, as we lack a clean specification, but this doesn’t seem to match any software development task I’ve seen outside of reverse engineering and the paper targets “holistic” software development.
2 - questionable test quality from synthetic pipeline
Due to the scale of the benchmark in comparison to the size of the research team, I see the use of a synthetic pipeline.
However, agents are spectacularly awful at writing good integration tests w/o human oversight (my claim from experience) and we can see this in the repo. Cmatrix (one of the tested libs) has very few tests checking the actual animation functionality of the library and a majority of the tests are unit tests checking CLI arg behavior. What tests do exist for animation just check that something happened.
An executable that produces an unsatisfactory animation, but handles the CLI args properly would score extremely high on the benchmark (and could even pass it).
This issue is fundamental to synthetic pipelines being used to create TBs. Without human oversight, it’s very hard to describe the use of software. It’s trivially easy for the model to enumerate the flags and create combinations and write hundreds of garbage tests.
3 - lack of replication
Each of the 200 tasks was ran w/ each of the 9 LMs once. LMs are non-deterministic and I believe that output quality varies more as turns increase (variance of a random walk).
It’s standard practice to use pass@k or make multiple runs to capture output variability and I don’t see a real reason that wasn’t done here.
I could see an argument for cost?, but less LMs or tasks could have been selected and I’m sure that the lab (Meta “Superintelligence”) has the budget to perform this run.
4 - lack of open source models
self-explanatory
5 - model memorization
Training on github repos is standard practice for LMs now and it’s made model/agent evaluation very difficult. There’s a real possibility of contamination here, especially w/ the newer models.
I’ll come back to this point in my experiment.
My experiment
So where does this leave us?
I have two goals I want to pursue from here:
- Recreate the experiment and note any learnings
- Improve on the methodology (multiple ideas I’m saving for a future post)
To do this, I made a fork that runs tasks w/ OpenRouter as the provider. I used deepseek-v4-flash because I don’t have a superintelligence sized budget (the 14 runs I made cost me ~4 buckaroos), but I’m planning to test more down the line.
I selected 3 C repos (cmatrix, bedtools2, doxygen) that most models did well on to recreate the runs for, because I’m the most competent w/ C out of the compilable languages the authors selected.
I used mini-swe-agent w/ the same sys prompt from the repo, and used the following task msg since I couldn’t find the original.
Write some tests for the existing executable, then write your own code and check if it passes. Complete once done by issung COMPLETE_TASK. If a binary errors with Error opening terminal or similar, it's a curses app — focus on --help, version, and error-path testing rather than trying to run it interactively. Use script -qc only if a specific test requires the binary to start successfully under a pty.
Experiment Results + Findings
Deepseek values are from my runs, other values are from the paper/website.
Note that pass rate is test pass %. No runs resulted in a 100% TB test, they all get partial scores.
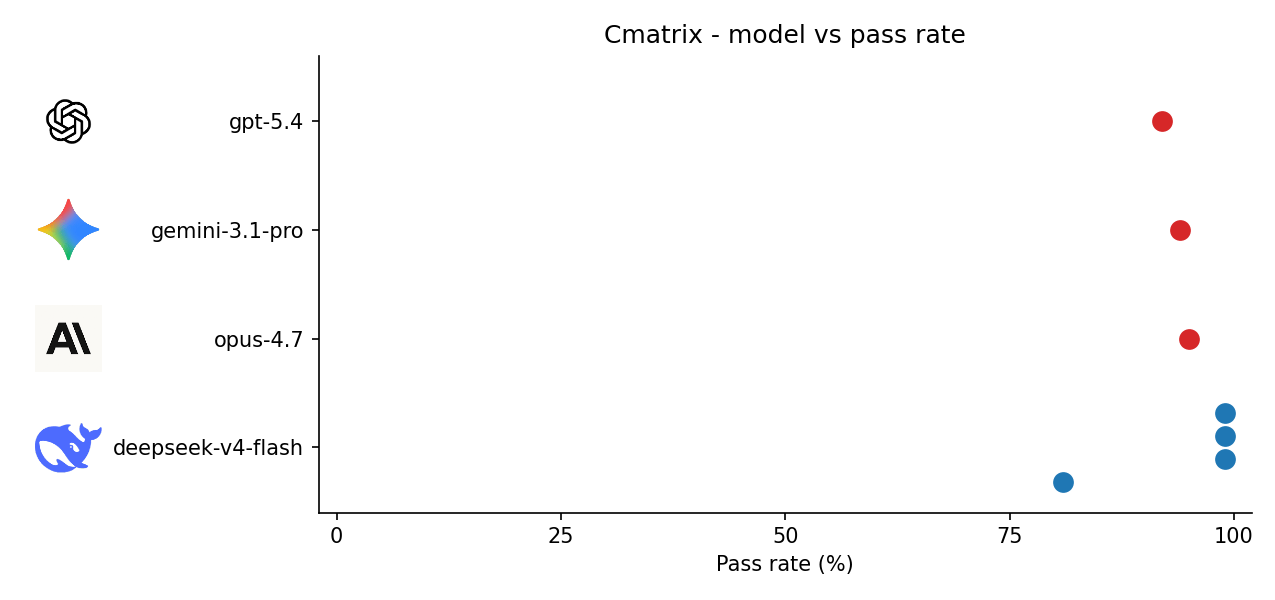
Cmatrix
I noticed that deepseek outputted the original authors in the headers of the code for 1 of 4 runs. Compared to the next 2 tasks, all the models did well leading me to believe that the models strongly memorized the original code, or the TB is trivial because the application is GUI focused and hard to test.
Runs 2-4 gave 99% TB pass rate (the code is different). I wonder if this is related to the provider (Novita through OpenRouter) potentially caching some of my calls.
| Model | Pass rate |
|---|---|
| deepseek-v4-flash | 81%, 99%, 99%, 99% |
| opus-4.7 | 95% |
| gemini-3.1-pro | 94% |
| gpt-5.4 | 92% |
Bedtools2 + Doxygen
0% deepseek runs are compile failures due to buggy code.
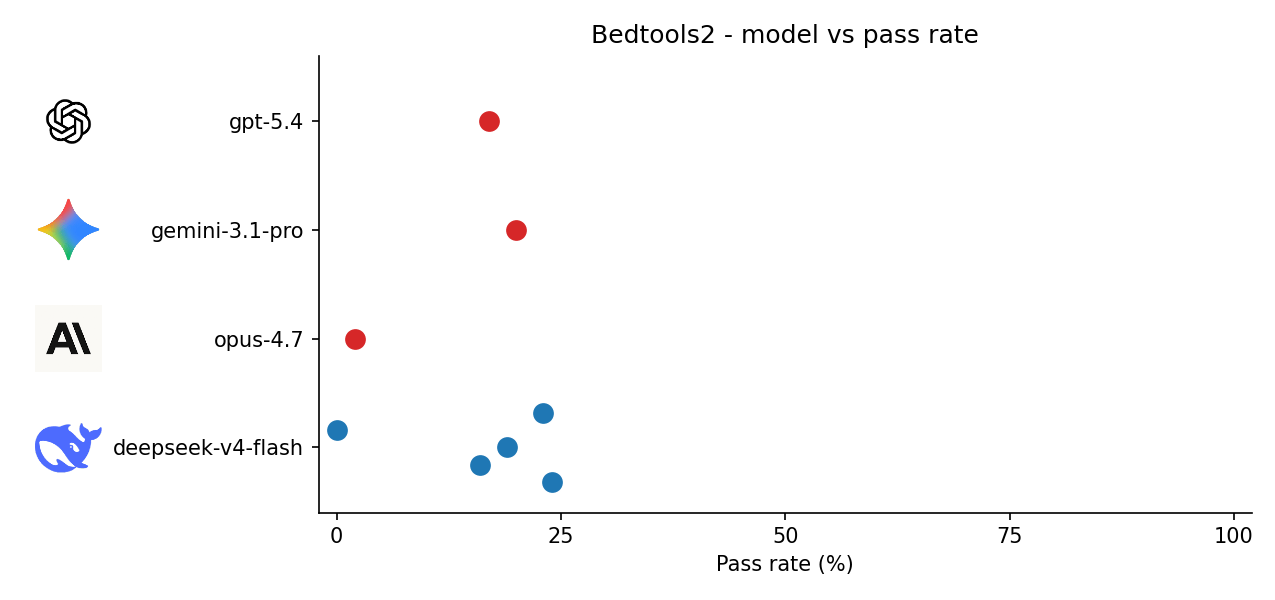
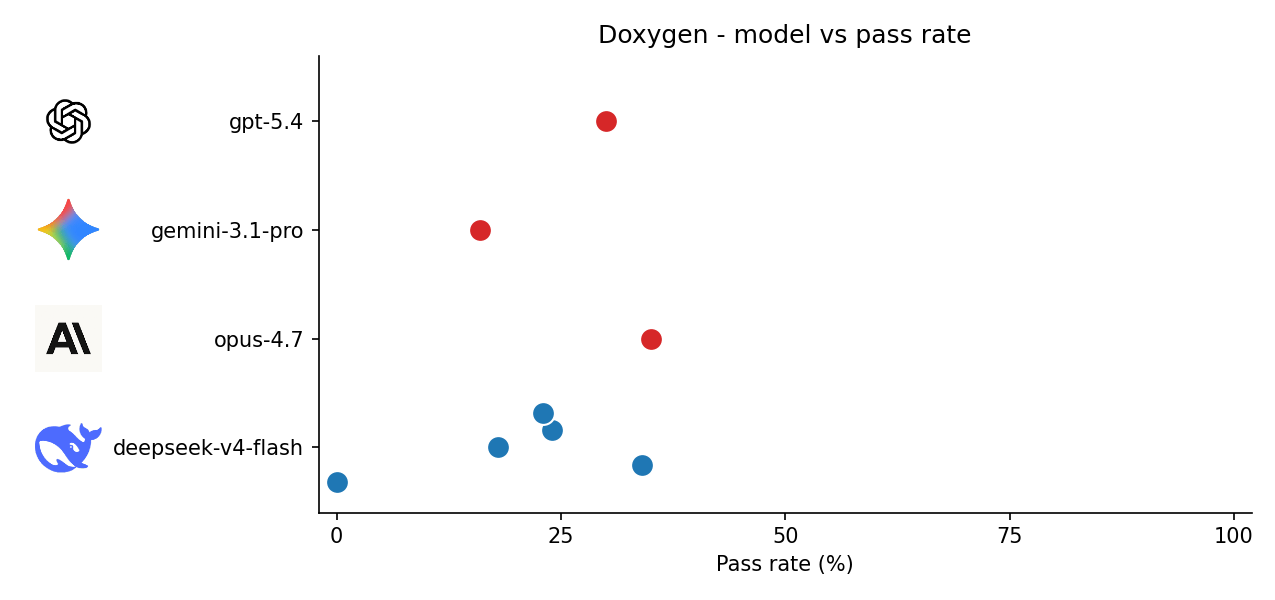
| Model | bedtools2 pass rate | doxygen pass rate |
|---|---|---|
| deepseek-v4-flash | 24%, 16%, 19%, 0%, 23% | 0%, 34%, 18%, 24%, 23% |
| opus-4.7 | 2% | 35% |
| gemini-3.1-pro | 20% | 16% |
| gpt-5.4 | 17% | 30% |
We can see that multiple runs of deepseek gave a big spread. I’m curious to see what the spread of the closed source models looks like.
Next Steps
-
Improve on methodology
-
Does the model creating the TB matter? Maybe Anthropic models performed a bit better here because Sonnet 4.5 created the TB
-
Investigate sensitivity of model performance to task prompt